Microsoft сделал возможным говорить на любом языке своим собственным голосом.
Говорить на иностранном языке собственным голосом? VALL-E X от Microsoft позволяет осуществлять межъязыковой синтез речи с нулевым искажением.

Современные модели синтеза голоса по-прежнему лучше всего работают при с конкретным диктором на конкретном языке. Межъязыковой синтез речи, целью которого является передача характеристик голоса пользователя с одного языка на другой, оставался относительно малоизученным. Но теперь ситуация изменилась.
В новой работе "Говорите на иностранных языках своим собственным голосом: Cross-Lingual Neural Codec Language Modeling”, исследовательская группа Microsoft VALL-E X представила, простую, но эффективную модель кросс-языкового нейрокодека, которая наследует сильные возможности обучения от модели VALL-E TTS и демонстрирует высококачественные показатели кросс-языкового синтеза речи.
Команда описывает свои исследования следующим образом:
Мы разрабатываем кросс-языковую языковую модель нейрокодека VALL-E X с использованием больших многоязычных многодоменных неочищенных речевых данных.
Многоязычная система обучения позволяет VALL-E X генерировать межъязыковую речь, сохраняя голос, эмоции и речевой фон невидимого диктора, на основе всего одного предложения на исходном языке.
Основываясь на способности моделирования межъязыковой речи с помощью введенного языкового идентификатора, VALL-E X может генерировать речь на родном языке для любого диктора и значительно уменьшить проблему иностранного акцента, которая является хорошо известной проблемой в задачах межъязыкового синтеза речи.

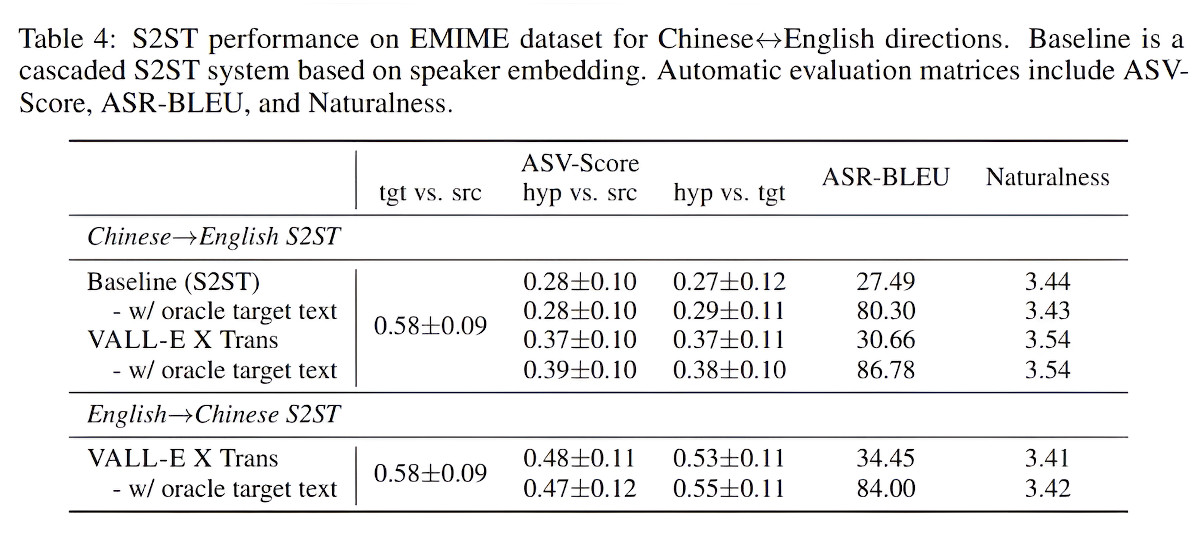
VALL-E X применяется для задач кросс-языкового синтеза текста в речь и перевода речи в речь. Эксперименты показывают, что VALL-E X может превзойти базовые решения по сходству с диктором, качеству речи, качеству перевода, естественности речи и оценке человеком.
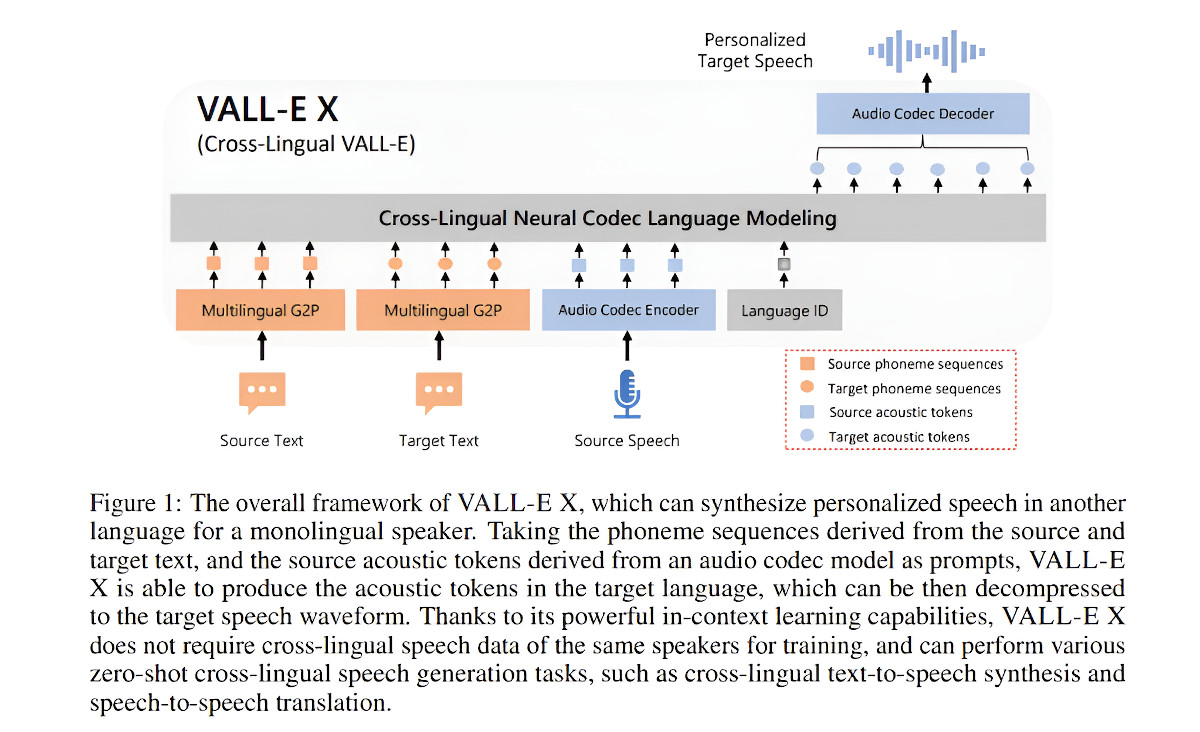
VALL-E X построен на основе VALL-E, нейронной модели кодека, представленной Microsoft в январе, которая демонстрирует сильные возможности обучения и достигает впечатляющей производительности синтеза речи. В данном исследовании VALL-E расширяется для обеспечения возможностей межъязыкового перевода речи в речь.
Сначала команда извлекает данные многоязычной транскрипции речи из данных ASR (автоматического распознавания речи) или псевдомаркированных речевых данных. Затем они используют конвертер на основе правил (преобразование графем в фонемы / инструмент G2P) для преобразования транскрипций в последовательности фонем; и автономный нейрокодек для преобразования речевых данных в акустические лексемы. Наконец, они обучают многоязычную модель, используя парные последовательности фонем и акустических лексем каждого языка.
Таким образом, обученная система VALL-E X способна по запросу одного предложения, произнесенного на исходном языке, генерировать высококачественную межъязыковую речь, которая сохраняет характеристики голоса диктора-источника, такие как эмоции и другую фоновую информацию.
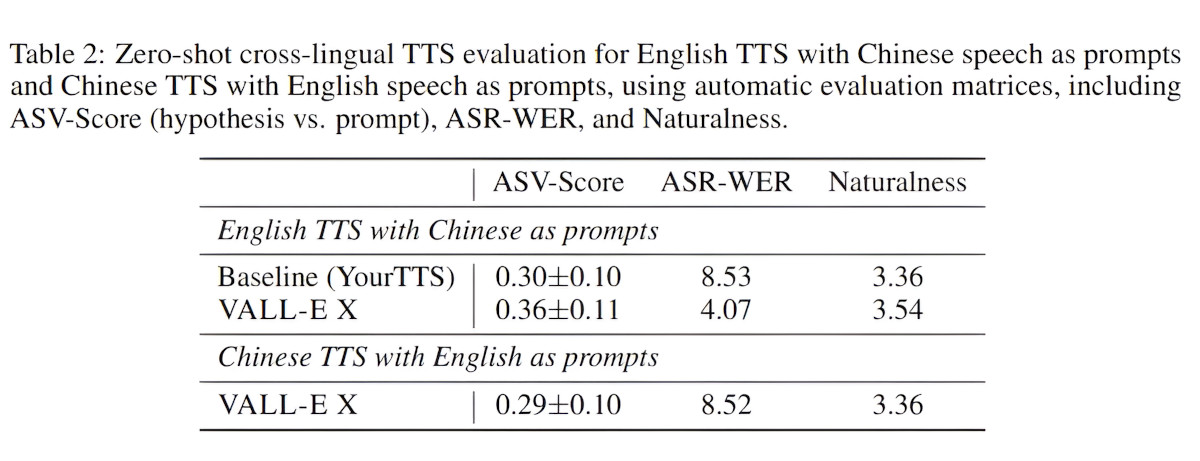
В ходе оценки VALL-E X превзошел сильные базовые модели, показав более высокие показатели сходства с диктором, более низкие показатели ошибок в словах, более высокие показатели BLEU и лучшую естественность речи.
В данной работе представлена перспективная модель с большим потенциалом для кросс-языкового синтеза речи. Дебютная версия VALL-E X была обучена на крупномасштабных данных транскрипции речи нескольких дикторов на китайском и английском языках, но исследователи планируют в будущем расширить свой подход, используя дополнительные данные и языки.